Open-Source Monitoring
for Generative AI
Thousands of users and organizations leverage Helicone to monitor their LLM applications. Instantly get insights into your latency, costs, and much more.
Open Source
Open-Source is more than a choice—it's a commitment to user-centric development, community collaboration, and absolute transparency.
Cloud Solution
We offer a hosted cloud solution for users that want to get up and running quickly.
Manage Hosted
Deploy Helicone on your own infrastructure to maintain full control over your data.
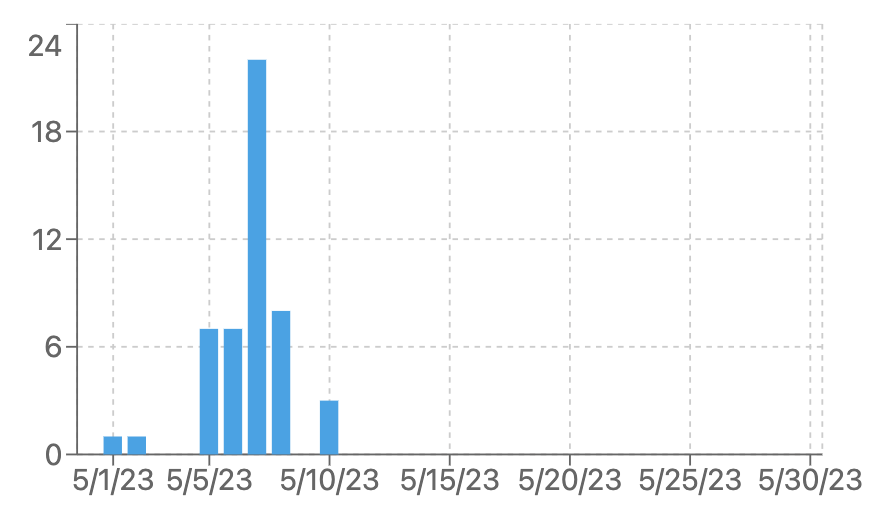
Real Time Metrics
Insights into your Usage and Performance
Building a Large-Language Model monitoring tool is time consuming and hard to scale. So we did it for you:
Monitor Spending: Keep a close eye on your AI expenditure to control costs
Analyze Traffic Peaks: Identify high-traffic periods to allocate resources more efficiently
Track Latency Patterns: Detect patterns in application speed and rectify slowdowns proactively
User Management Tools
Easily manage your application's users
Our intuitive user management tools offer a hassle-free way to control access to your system.
User Rate Limiting: Limit the number of requests per user to prevent abuse
User Metrics: Identify power users and optimize your application for them
Request Retries: Automatically retry failed requests to ensure users aren't left in the dark
Tooling for LLMs
Tools to scale your LLM-powered application
Our toolkit provides an array of features to manage and control your AI applications.
Bucket Cache: Save money by caching and configuring responses
Custom Properties: Tag requests to easily segment and analyze your traffic
Streaming Support: Get analytics into streamed responses out of the box
Made By Developers, For Developers
Simple and Flexible Integration
Our solution is designed to seamlessly integrate with your existing setup:
Effortless Setup: Get started with only 2 lines of code
Versatile Support: Our platform smoothly integrates with your preferred tool
Package Variety: Choose from a wide range of packages to import
import { Configuration, OpenAIApi } from "openai";const configuration = new Configuration({apiKey: process.env.OPENAI_API_KEY,// Add a basePath to the ConfigurationbasePath: "",baseOptions: {headers: {// Add your Helicone API Key"Helicone-Auth": "Bearer <YOUR_API_KEY>",},}});const openai = new OpenAIApi(configuration);
Example Integration with OpenAI
Frequently Asked Questions
Can’t find the answer you’re looking for? Join our Discord server or contact us directly.
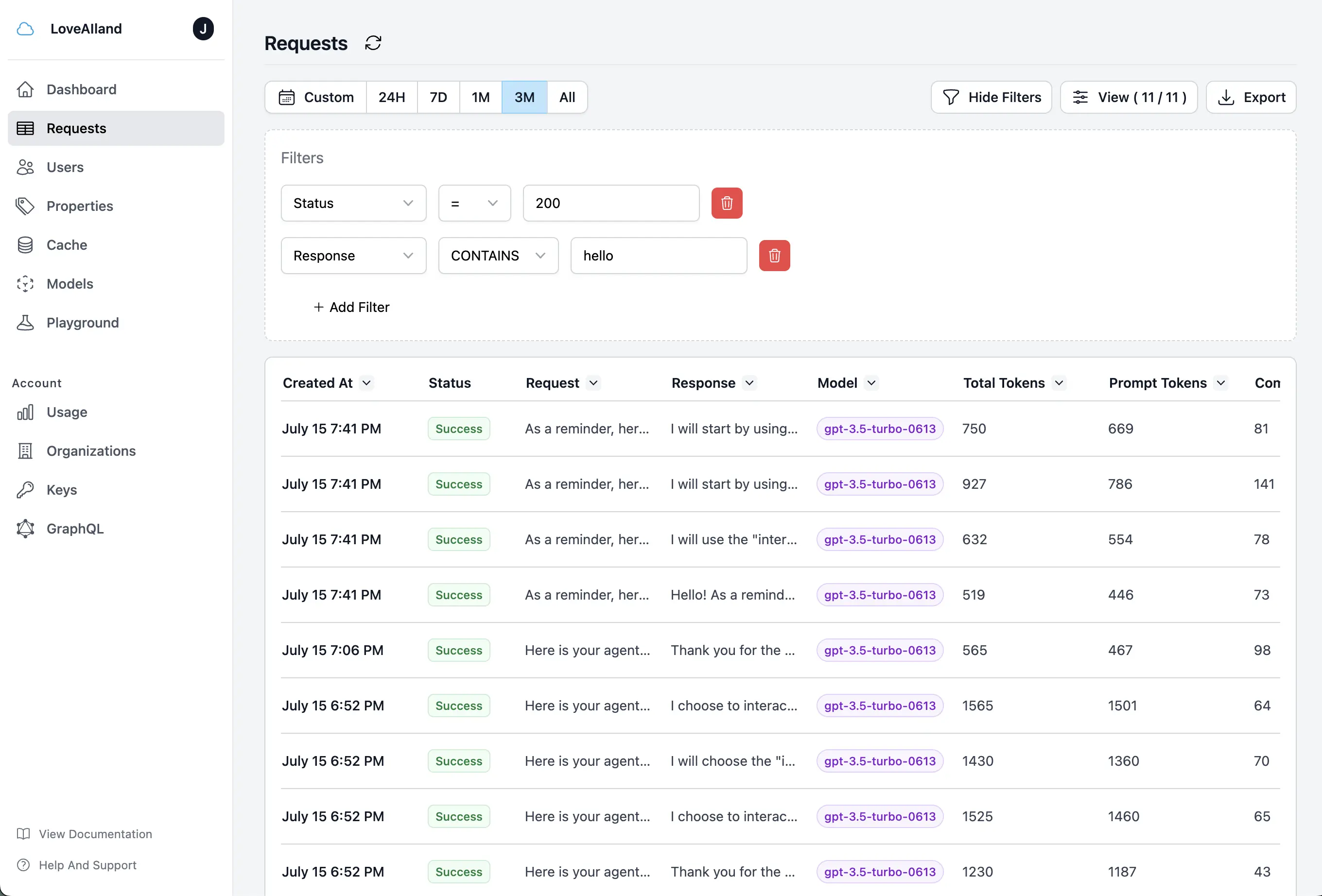
How does Helicone work under the hood?
Our recommended integration is via a proxy, but we also support an async logging integration. We log the request and response payloads, and use that to build a user-level view of your LLM usage.
What is the latency impact?
We know latency is a huge concern for your LLM-powered application, so we use Cloudflare Workers to ensure the latency impact is negligible. You can read more about our architecture here.
I do not want to use a proxy. What are my options?
We have an async logging integration for users that do not want to use a proxy. We also provide a self-hosted version of our proxy for users that want to host it themselves.